
按照属性A划分样本集分别得到的两个子集(A取值T和A取值F)的信息熵分别为:

按照属性B划分样本集分别得到的两个子集(B取值T和B取值F)的信息熵分别为:

因此,决策树归纳算法将会选择属性A。
(2)
划分前的Gini值为G=1-0.42-0.62=0.48
按照属性A划分时Gini指标:
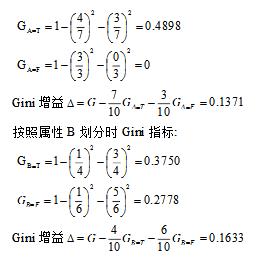
因此,决策树归纳算法将会选择属性B。
 (1)计算按照属性A和B划分时的信息增益。决策树归纳算法将会选择哪个属性? (2)计算按照属性A和B划分时Gini系数。决策树归纳算法将会选择哪个属性?
(1)计算按照属性A和B划分时的信息增益。决策树归纳算法将会选择哪个属性? (2)计算按照属性A和B划分时Gini系数。决策树归纳算法将会选择哪个属性? (简答题)
考虑下表数据集,请完成以下问题: (1)估计条件概率。 (2)根据(1)中的条件概率,使用朴素贝叶斯方法预测测试样本(A=0,B=1,C=0)的类标号; (3)使用Laplace估计方法,其中p=1/2,l=4,估计条件概率。 (4)同(2),使用(3)中的条件概率。 (5)比较估计概率的两种方法,哪一种更好,为什么?
(填空题)
分类器设计阶段包含三个过程:划分数据集、分类器构造和()
(简答题)
下表所示的相依表汇总了超级市场的事务数据。其中hot dogs指包含热狗的事务,指不包含热狗的事务。hamburgers指包含汉堡的事务,指不包含汉堡的事务。 假设挖掘出的关联规则是“hot dogs=>hamburgers”。给定最小支持度阈值25%和最小置信度阈值50%,这个关联规则是强规则吗? 计算关联规则“hot dogs=>hamburgers”的提升度,能够说明什么问题?购买热狗和购买汉堡是独立的吗?如果不是,两者间存在哪种相关关系?
(简答题)
数据聚合需要考虑的问题有哪些?
(简答题)
一个数据库有5个事务,如表所示。设min_sup=60%,min_conf=80%。 (a)分别用Apriori算法和FP-growth算法找出所有频繁项集。比较两种挖掘方法的效率。 (b)比较穷举法和Apriori算法生成的候选项集的数量。 (c)利用(1)所找出的频繁项集,生成所有的强关联规则和对应的支持度和置信度。
(简答题)
数据集如下表所示: (a)把每一个事务作为一个购物篮,计算项集{e},{b,d}和{b,d,e}的支持度。 (b)利用(a)中结果计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。置信度是一个对称的度量吗? (c)把每一个用户购买的所有商品作为一个购物篮,计算项集{e},{b,d}和{b,d,e}的支持度。 (d)利用(b)中结果计算关联规则{b,d}→{e}和 {e}→{b,d}的置信度。置信度是一个对称的度量吗?
(多选题)
下面属于数据集的一般特性的有:()。
(填空题)
数据集分为三类:()。
(简答题)
考虑如下的频繁3-项集:{1,2,3},{1,2,4},{1,2,5},{1,3,4},{1,3,5},{2,3,4},{2,3,5},{3,4,5}。 (a)根据Apriori算法的候选项集生成方法,写出利用频繁3-项集生成的所有候选4-项集。 (b)写出经过剪枝后的所有候选4-项集。

